

2023
Company Overview
One of the top garment was established in Indonesia in 1980. The company specializes in creating fabrics and apparel for ready-to-wear. They sell uniforms, women’s clothing, children’s clothing, and sportswear. They cater to the international market and manufacture their goods in a number of nations, including Ethiopia, Vietnam, and Indonesia.
As a corporation that relies largely on SAP’s reliable software solutions, it is more important than ever to improve our vital business processes’ disaster recovery capabilities. We are determined to strengthen our DR plans and use SAP’s expertise to protect against unexpected disruptions and minimize any potential negative impact on our operations because we understand how important uninterrupted functionality is.
Problem statement
The company has an SAP system, where they manage their organizations through many business processes such as Finance, Accounting, Production and Logistics. Along with their business growth,they face several challenges such as server capacity issues, data growth rate, maintenance and operation costs, scalability requirements, and the need for flexible infrastructure to adjust future business growth.
The company’s infrastructure has had hardware issues, which have caused SAP system downtime and missing schedule backups. As a result, this organization needs a quick, powerful, and secure resource server that can run SAP without sacrificing security features. They have tested their non-core applications on AWS before deciding to migrate their SAP applications to the cloud.
Because the plan is for the SAP Server to be in the AWS Cloud, the company also needs to implement a disaster recovery strategy with an RTO and RPO of less than 10 minutes. They face challenges in ensuring their disaster recovery solution is adaptable. They need to accommodate future growth while maintaining an efficient and critical business system.
Test the recovery procedures frequently to confirm their efficacy. To ensure that the recovery processes achieve the necessary RTO and RPO targets, run simulated disaster scenarios. Through testing, possible problems or workflow bottlenecks in the recovery process are found and fixed.
Additionally, we continuously use AWS CloudWatch and other monitoring tools to keep an eye on the backup and recovery procedures. Review and modify the solution frequently to find opportunities for development and make sure it keeps up with changing company requirements.
Proposed solution & architecture
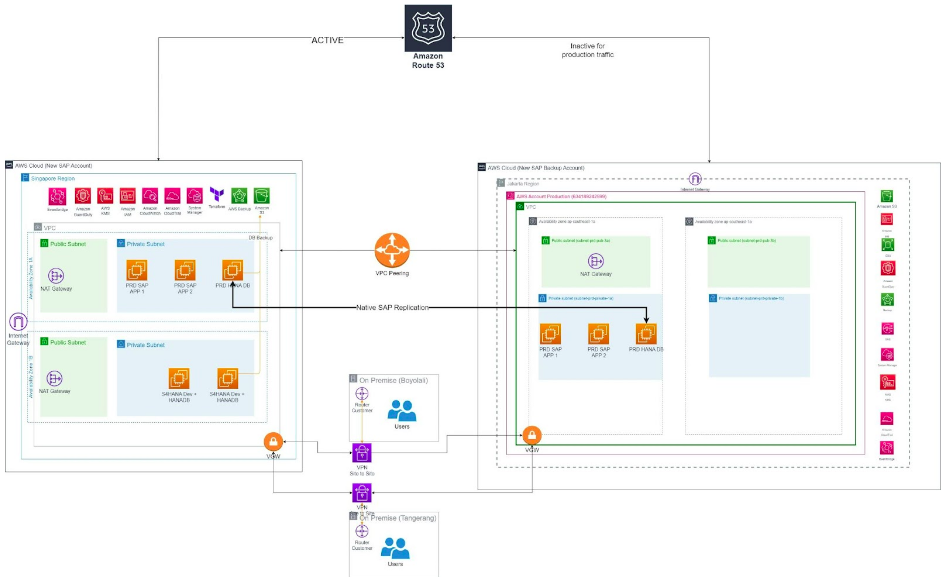
The design architecture above is made and offered to the customer, based on the best practice solution for Web Application on AWS.
- This project will be conducted in the AWS Singapore Region as Production Region and AWS Jakarta Region as Disaster Recovery Region.
- In this solution, the customer will have 2 AWS accounts. This Account will have limited access to the IT internal team.
- Deployment for each account will use 1 VPC in 2 AWS Availability Zone (AZ) for Production, and each AZ will have 2 subnets (public subnet and private subnet).
- There will be NAT Gateway in each Availability Zone, so the traffic to/from each instance can have direct internet connection and access.
- AWS Backup will be used as a media disaster recovery, where the backup server can be launched in the AWS Jakarta Region.
- AWS Route53 will be used for DNS management. Failover using Route 53 Private DNS is a highly reliable and automated process that ensures seamless continuity of service by directing traffic from a primary IP address in the Singapore region to an EC2 server in the Jakarta region. This setup also includes a warm standby backup for enhanced redundancy and fault tolerance.
- VPC peering in AWS allows to establish a private network connection between two Amazon Virtual Private Clouds (VPCs) that are located in the same region or different regions. In this case, we use VPC peering to facilitate native SAP replication between two EC2 instances.
- To make the environment more secure, the access will be limited.
- AWS IAM user will be created limited (in production account only for main administrator).
- For IT Internal Team must use VPN site to site from office or branch to access the environment.
- AWS KMS will be used for data at-rest encryption.
- AWS GuardDuty will be use for threat detection services that continuously monitors your AWS accounts and workloads for malicious activity and delivers detailed security findings for visibility and remediation.
- AWS Cloudtrail will be used to monitor governance, compliance and risk in customer AWS account.
Implementing a scaled-down, fully working replica of our production setup in another location is one suggestion for improving warm standby backup resilience. This strategy expands on the idea of warm standby and provides a shorter recovery time objective (RTO), as our workload is always active in a different Region.
We make sure that essential resources and parts needed for our production system are readily available by maintaining a warm standby environment. Important servers, databases, and network infrastructure are included in this. The standby environment is sufficiently provisioned to meet our workload in a disaster recovery scenario, even if it might not scale as well as our primary production environment.
The testing and continuous testing processes that are necessary to boost confidence in our disaster recovery capabilities are made easier by having a warm standby arrangement. In the standby environment, we may run routine simulations and testing without disrupting our core production system. This enables us to recognize any problems or flaws in our recovery processes and fix them, resulting in a smoother transition during a real disaster occurrence.
Overall, by providing an always-on backup system in another region, the warm standby technique strengthens our resilience. It reduces downtime, facilitates quicker recovery, and gives us the ability to thoroughly test and validate our disaster recovery plans.
Metrics for success
These metrics include:
- Recovery Time Objective (RTO): The time it takes to recover and restore the production environment in the standby region using native SAP replication. The RTO less than 10 minutes indicat-es a more successful warm standby backup resilience strategy.
- Recovery Point Objective (RPO): The point in time to which data can be recovered after a disaster. The RPO less than 10 minutes signifies a more successful implementation of native SAP replication, as it indicates minimal data loss during the recovery process.
- Availability: The percentage of time the warm standby environment is operational and accessible. Higher availability indicates a more successful implementation of native SAP replication, ensuring continuous sync.
- Testing and Validation: The percentage of successful tests and validation activities performed in the standby environment using native SAP replication.
Lesson learned
Make sure we have done extensive planning and preparation before beginning the DR approach. This involves putting together a thorough plan for downtime and making sure the appropriate teams are working on the process.
Re:Invent Go:Beyond
