
Building a Resilience Infrastructure


What is Resilience ?
Resiliency refers to the ability of a workload to withstand and recover from various types of failures or disruptions. It involves designing and implementing measures to ensure that the system remains available, reliable, and functional even in the face of unexpected events.
Resiliency is crucial because workload and services are vulnerable to a range of issues, such as hardware failures, network outages, power disruptions, natural disasters, and cyber attacks. These events can potentially cause downtime, data loss, or service interruptions, leading to financial losses and negative impacts on businesses and users.
To achieve resiliency, there are several key practices and technologies are commonly employed:
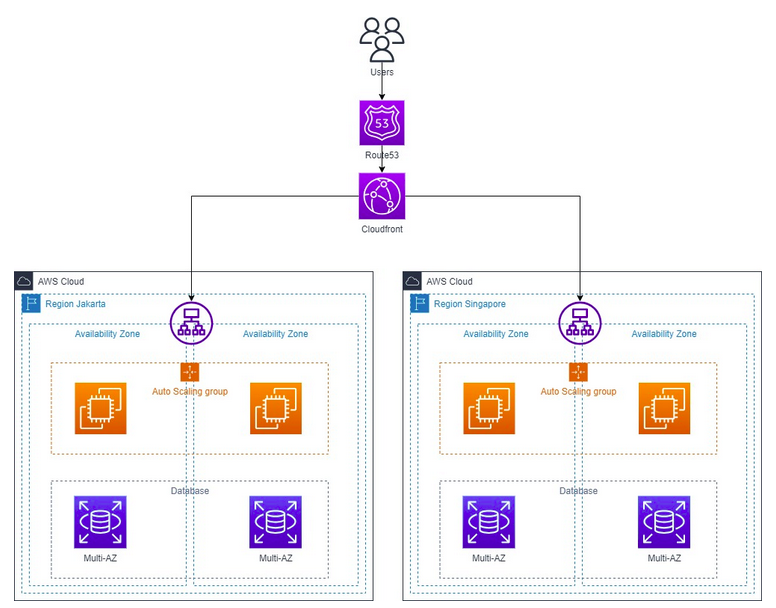
- Redundancy : This involves duplicating critical components, such as servers, storage systems, and networking infrastructure, across different geographical locations or availability zones. If one component fails, the redundant components can take over seamlessly, ensuring continuity of service.
- Load balancing : Distributing incoming network traffic across multiple servers or instances helps prevent overload on any single resource. Load balancing ensures that if one server or instance fails, the traffic is automatically routed to others, minimizing the impact on users.
- Scalability : The ability to scale resources up or down based on demand is vital for resiliency. By dynamically allocating additional resources during peak loads or scaling down during low activity, cloud systems can maintain performance and availability.
- Data replication and backups : Storing copies of data in multiple locations helps protect against data loss. Regularly backing up data and ensuring its integrity allows for recovery in case of accidental deletion, corruption, or system failures.
- Fault tolerance and self-healing : Building systems that can detect failures and automatically recover from them reduces manual intervention and downtime. Automated processes can identify issues, trigger remediation actions, and restore services without requiring human intervention.
- Disaster recovery planning : Developing comprehensive plans for handling catastrophic events ensures that critical systems and data can be restored efficiently. This may involve replicating data and resources to remote locations, implementing backup strategies, and establishing recovery procedures.
- Monitoring and alerting : Continuous monitoring of cloud resources, network connectivity, performance metrics, and security events helps detect potential issues and enables proactive actions. Real-time alerts and notifications allow for timely responses to mitigate risks and minimize disruptions.
By incorporating these practices and technologies, organizations can enhance the resiliency of their workload environment, enabling them to deliver consistent, reliable services even in the face of various challenges and failures.
Resilience on AWS @ ICS Compute 2023
Resiliency on AWS

The AWS Well-Architected Framework defines resilience as having “the capability to recover when stressed by load (more requests for service), attacks (either accidental through a bug, or deliberate through intention), and failure of any component in the workload’s components.”
A resilient workload not only recovers, but recovers in an amount of time that is desired. This is often called a recovery time objective (RTO). Within a workload, there is often a desire to not degrade, but to be capable of servicing the workload’s requests during the recovery of a component. The study and practice of this implementation is known as Recovery Oriented Computing.
The other factors impacting workload reliability are:
- Operational Excellence , which includes automation of changes, use of playbooks to respond to failures, and Operational Readiness Reviews (ORRs) to confirm that applications are ready for production operations.
- Security, which includes preventing harm to data or infrastructure from malicious actors, which would impact availability. For example, encrypt backups to ensure that data is secure.
- Performance Efficiency, which includes designing for maximum request rates and minimizing latencies for your workload.
- Cost Optimization, which includes trade-offs such as whether to spend more on EC2 instances to achieve static stability, or to rely on automatic scaling when more capacity is needed.
In summary, to meet the business resilience requirements, there are several factors that need to be considered when designing the workload environment : design complexity, cost to implement, operational effort, security complexity, environmental impact. There will always be trade-offs that need to be considered also when we design the workload.
